Spark数据缓存机制及错误容忍机制
本文将重点介绍Spark框架中两个关键特性:数据缓存机制和错误容忍机制。数据缓存机制使得数据能够在内存中共享和重复使用,从而极大地提高了任务的执行速度。错误容忍机制则保证了即使在分布式环境中出现故障或错误,Spark仍能保持稳定运行,从而提供可靠的数据处理。
Spark数据缓存机制
理解Spark的数据缓存机制,首先需要回答以下几个问题:
- 哪些数据需要缓存:多个job共同依赖的、会被重复使用的中间数据。这类数据一旦缓存起来可以避免重复计算以减少job的执行时间。此外,被缓存的数据也不宜过大,数据过大内存不足时虽然可以存在磁盘,但磁盘I/O同样是个耗时操作,有时甚至不如重新计算快。
- 缓存操作会立即执行吗:缓存操作cache()是个lazy操作,不会立即执行。即执行到cache()操作时,只标记这个RDD需要被缓存到内存中,并不执行真正的缓存操作,只有等到遇到action()操作触发job运行时才会实际执行缓存操作。当需要缓存的RDD中的record被计算出来时,及时进行缓存。
- 包含缓存时如何生成DAG图:Spark首先假设应用没有数据缓存,照常生成DAG。然后将被缓存的RDD前所有的RDD都去掉,得到削减后的DAG图。最后按照正常的规则将DAG图转为stage和task。
缓存写入与缓存读取(memoryStore)
Spark在每个Executor进程中分配一个区域(memoryStore)来进行数据缓存,该区域由BlockManager来管理。由下图所示,menoryStore中包含了一个LinkedHashMap,用来存储RDD的分区。该LinkedHashMap的Key是blockId,即rddId+partitionId,value是分区中的数据
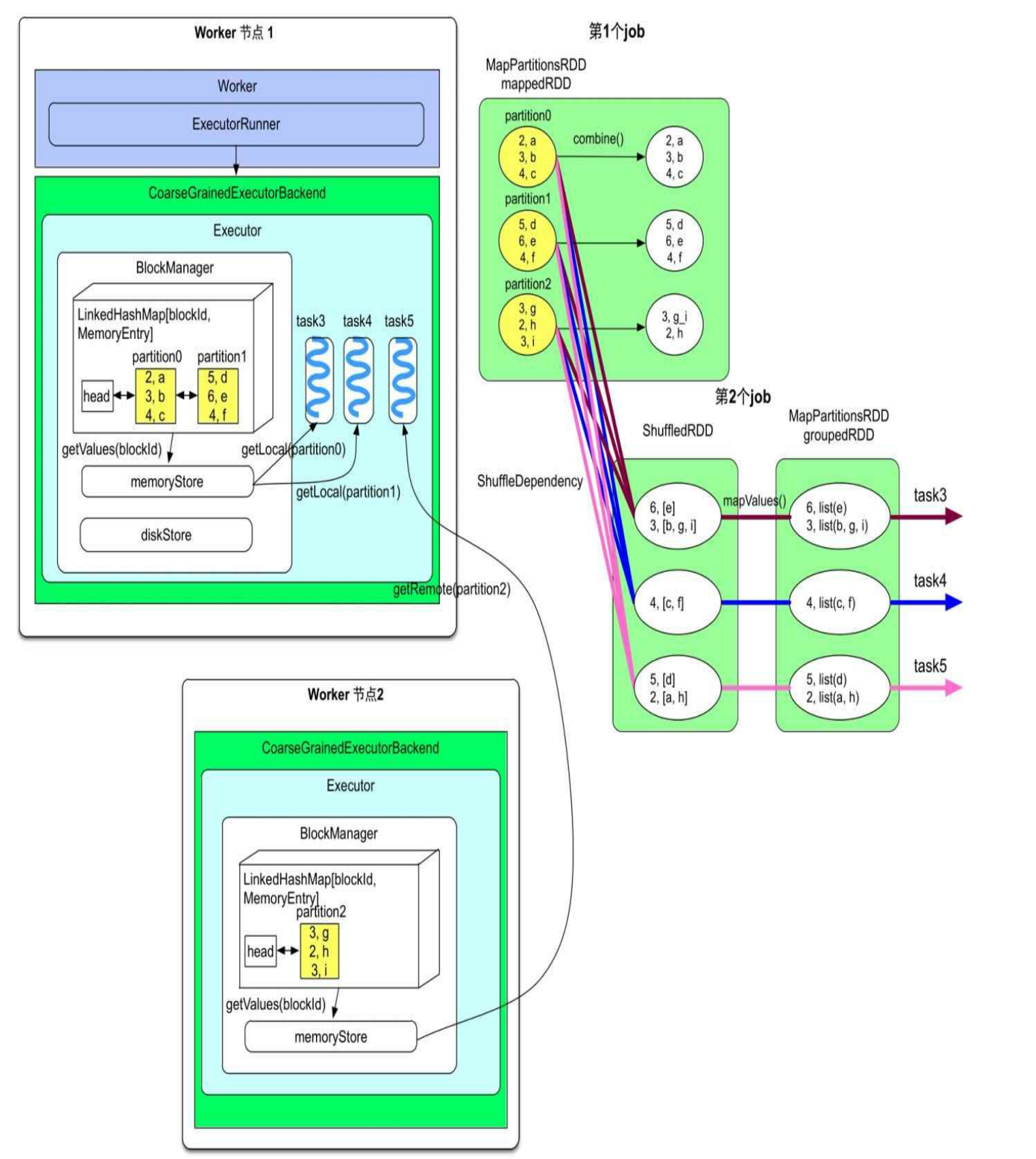
在上图的例子中,mappedRDD的partition0和partition1被worker节点1中的BlockManager缓存,而partition2被worker节点2中的BlockManager缓存。对于图中的第2个job来说,它的3个task都被分到了worker节点1上,其中task3和task4对应的CachedPartition在本地,因此可以直接通过Worker节点1的menoryStore读取,而task5对应的CachedPartition在节点2上,需要远程访问。
注:缓存机制只适用于每个Spark应用内部,即缓存数据只能在job之间共享,应用之间不能共享缓存数据
缓存的替换与回收
- 自动缓存替换:缓存替换指的是当需要缓存的RDD大于当前可利用的空间时,使用新的RDD替换掉旧的以腾出空间。Spark采用LRU(Least Recently Used)替换算法,即优先替换掉当前最长时间没有被使用过的RDD。
- 主动缓存回收:除了自动缓存替换外,Spark还允许用户通过unpersist()操作自己设置回收的RDD和回收时间。不同于persist()的延时生效,unpersist()是立即生效的。
与MapReduce缓存机制的对比
- 它的缓存机制主要基于磁盘存储,将中间计算结果写入磁盘,以便后续任务可以从磁盘读取并继续处理。这种机制可以减少重复计算和提高任务的容错能力,但由于涉及磁盘读写,对于迭代式算法和需要频繁访问中间结果的任务来说,性能不够高效
- Spark提供了内存缓存机制。Spark的RDD可以在集群的内存中持久化,以便后续任务可以更快地访问它们。因为数据可以在内存中共享和重复使用,避免了磁盘读写的开销,可以实现更高的性能。此外,Spark的缓存机制也更加灵活,它允许开发人员在需要时手动选择哪些数据需要缓存,以及选择缓存数据的存储级别。
错误容忍机制
错误容忍机制就是在应用执行失败时能够自动恢复应用执行,并且执行结果与正常执行时得到的结果一致。
Spark通过以下两个方法实现错误容忍:
- 重新计算机制,主要用来解决软硬件故障导致的job执行失败问题
- Checkpoint机制,主要用来解决计算链很长情况下的数据丢失问题
重新计算机制
这种机制通过重新执行计算任务来实现错误容忍。当job抛出异常不能继续执行时,重新启动计算任务,再次执行。
- 从哪里开始重新计算:Spark将会以Stage的粒度进行重新计算。原因在于:Spark采用了延时删除的策略,即将上游stage的Shuffle Write的结果写入本地磁盘,这部分数据只有在job完成后才会删除。因此即使当前stage计算失败,上一个stage由于输出数据还在磁盘上无需重复计算,只需重复计算当前stage即可。由此可见,Spark根据宽依赖切分出的stage既保证了task的独立性,也方便了错误容忍的重新计算。
- 怎样计算丢失数据:Spark采用了一种称为lineage的数据溯源方法,其核心是在每个RDD中记录其上游数据是什么,以及当前RDD是如何通过上游RDD得到的。这样在错误发生时,可以根据lineage找到计算当前RDD所需的计算链以进行重复计算。
Checkpoint机制
Checkpoint机制的意义
重新计算机制有一个缺点,如果某个RDD的计算链过长,那么重新计算该数据的代价比较高。对于这一问题,Spark同时提供了Checkpoint机制,它可以将计算过程中某些重要数据进行持久化,这样在再次执行时可以从检查点执行,从而减少重新计算的开销。
Checkpoint的目的就是对重要数据进行持久化,在节点宕机时也能够恢复,因此需要可靠地存储。此外checkpoint的数据量可能很大,因此需要大的存储空间,一般使用HDFS来进行持久化。
在已经有了缓存机制的情况下,并且前一个Stage的输出也会存在磁盘上,为什么还需要checkpoint机制呢?
- 首先, 前一个stage虽然通过Shuffle Write将输出写到磁盘上,但是磁盘并不可靠,可能随着节点宕机而丢数据。并且这部分在磁盘上的数据会随着job完成而被清空,无法被下一个job使用
- 其次,被缓存的数据由于内存大小的限制,容易被替换和回收而丢失,也不能提供充足的可靠性。
所以,对于串联执行的job,尤其是迭代型job,需要每隔几个job就对一些中间数据进行checkpoint,这样在出错时可以从最近的checkpoint数据恢复执行。
Checkpoint机制的实现
用户设置rdd.checkpoint()后只是标记了这个rdd需要持久化,这时计算过程也像正常一样计算。不同的是,一旦设置了checkpoint,等到当前job计算结束后,会再重新启动一个专门的job重新计算一遍这个rdd,并将其checkpoint。在这个专门的job中,每计算出一个record,就将其持久化写入HDFS。
由此可见,checkpoint额外启动job来进行持久化的过程会增加计算开销。为了解决这个问题,最好先将需要被checkpoint的数据进行缓存,这样额外启动的job只需要对缓存数据进行checkpoint即可,无需重新计算这个RDD,以便节约计算开销。
当一个RDD完成checkpoint之后,Spark会建立一个新的RDD,类型为ReliabeCheckpointRDD,用来表示被checkpoint到磁盘上的RDD。由于Spark认定这个RDD已经被持久化到稳定的HDFS上,之后无需被重复计算,因此会将这个新的ReliabeCheckpointRDD的lineage截断,不再保留它的计算链。
Checkpoint机制与缓存机制的区别
- 目的不同:缓存机制的目的是加速计算,checkpoint机制的目的是为了错误容忍。
- 存储位置不同:缓存机制为了读写速度快,主要使用内存。checkpoint为了数据的可靠性,主要使用HDFS
- 写入数据速度不同:缓存数据写入较快,对job执行影响小,会在job运行时进行缓存。checkpoint时写入速度慢,为了避免影响当前job的计算时延,会额外启动专门的job来进行持久化。
- 对lineage的影响不同:checkpoint机制将切断被持久化了的RDD的lineage,而缓存机制会保留被缓存的RDD的lineage。因为Spark认为缓存的数据并不可靠,一旦丢失还需要根据lineage重新计算,而通过checkpoints持久化了的数据是可靠的