History of data platform architecture

Data warehousing:
The history of data warehousing started with helping business leaders get analytical insights by collecting data from operational databases into centralized warehouses, which then could be used for decision support and business intelligence (BI). Data in these warehouses would be written with schema-on-write, which ensured that the data model was optimized for downstream BI consumption.

Challenge:
- Couple compute and storage, can not scale respectively.
- More and more datasets were completely unstructured, e.g., video, audio, and text documents, which data warehouses could not store and query at all.
- Most organizations are now deploying machine learning and data science applications, but these are not well served by data warehouses. None of the leading machine learning systems, such as TensorFlow, PyTorch and XGBoost, work well on top of warehouses. Unlike BI queries which extract a small amount of data, these systems need to process large datasets using complex non-SQL code. Reading this data via ODBC/JDBC is inefficient, and there is no way to directly access the internal warehouse formats.
Data lake
Starting from 2010s,
Low-cost storage systems with a file API that hold data in generic open file formats, such as Apache Parquet and ORC. This approach started with the Apache Hadoop movement, using the Hadoop File System (HDFS) for cheap storage. Starting from 2015, cloud data lakes, such as S3, ADLS and GCS, started replacing HDFS. The data lake was a schema-on-read architecture that enabled the agility of storing any data at low cost, but on the other hand, caused the problem of data quality and governance. The use of open formats made data lake data directly accessible to a wide range of other analytics engines, such as machine learning systems. And a small subset of data in the lake would later be ETLed to a downstream data warehouse (such as Teradata, Redshift or Snowflake) for the most important decision support and BI applications. This two-tier data lake + warehouse architecture is now dominant in the industry.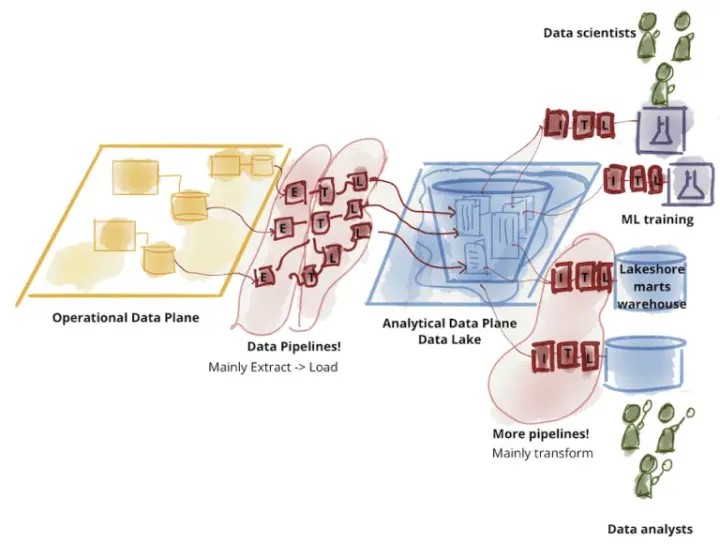

Challenge:
- In the first generation platforms, all data was ETLed from operational data systems directly into a warehouse. In today’s architectures, data is first ETLed into lakes, and then again ELTed into warehouses. The increased number of ETL/ELT jobs, spanning multiple systems, increases the complexity and the probability of failures and bugs.
- Reliability: Keeping the data lake and warehouse consistent is difficult and costly
- Data staleness. The data in the warehouse is stale compared to that of the data lake, with new data frequently taking days to load.
- Cost: Apart from paying for continuous ETL, users pay double the storage cost for data copied to a warehouse, and commercial warehouses lock data into internal formats that increase the cost of migrating data or workloads to other systems.
- Lack of data management: Such as ACID transactions, data versioning and indexing
Lakehouse
Currently, cloud datawarehouse systems have all added support to read external tables in data lake formats. However, these systems cannot provide any management features over the data in data lakes (e.g., implement ACID transactions over it) the same way they do for their internal data.
A more feasible way is building the metadata layer based on data lake, to combine these advantage of both data lake and data warehouse.
- SQL Performance and management features of data warehouses
- Low cost, open format accessible by a variety of systems , and machine learning/data science support of data lake

Apache Hive metastore also can tracks which data files are part of a Hive table at a given table version using an OLTP DBMS(metadata layer) and allows operations to update this transactionally. Buy there are some difference between LakeHouse solution and Apache Hive:
- Data Quality and Governance: Hive does not provide built-in mechanisms for data quality checks or schema enforcement, making it less suitable for enforcing data governance policies. Lakehouse solution such as Delta Lake, on the other hand, provides schema enforcement and supports data quality checks through the use of constraints, allowing users to ensure data integrity and enforce governance policies.
- Data Consistency and Reliability: Hive provides eventual consistency, meaning that changes made to the data may not be immediately reflected in queries until the data is fully loaded, making it suitable for batch processing. Lakehouse solution such as Delta Lake, on the other hand, provides strong consistency and reliability by supporting ACID transactions, ensuring that data operations are atomic and isolated. This makes it suitable for both batch and real-time processing scenarios.
- Data Operations: Hive supports SQL-like queries and a high-level language called HiveQL for processing and analyzing data. Lakehouse solution such as Delta lake and Iceberg not only support SQL operation like SparkSQL, but also support dataframe API for machine learning system to interact with it.
- Hive needs to an independent OLTP DBMS metastore as metadata layer. When the data partition is particularly large, theperformance of metastore is insufficient, which causes the query performance can not meet the business needs. Lake house solutions such as Delta lake and Iceberg, on the other hand, build its metadata layer based on blob storage, which can easily scale.
Key techniques for Lakehouse solutions to implement SQL performance optimizations:
- Caching: cache files from the cloud object store on faster storage devices such as SSDs and RAM on the processing nodes
- Auxiliary data: Lakehouse solution such as Delta Lake will maintain column min-max statistics for each data file, which enables data skipping optimizations when the base data is clustered by particular columns
- Data layout: records are clustered together and hence easiest to read together. Lakehouse solution such as Delta Lake support ordering records using individual dimensions or spacefilling curves such as Z-order