Apache Hive
Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
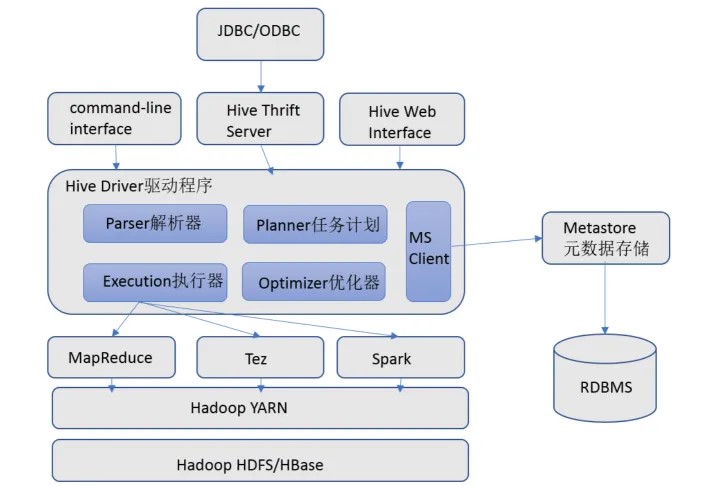
系统架构
- 对外接口:包括命令行,Web界面,Thrift接口,JDBC等
- Driver驱动器:管理HiveQL的生命周期,通过编译器和优化器创建执行计划,通过执行器执行执行计划。解析器将 SQL 字符串转换成抽象语法树 AST,并对抽象语法树进行分析,比如判断字段是否存在、类型是否合理等,编译器负责将 AST 编译成逻辑执行计划,并由优化器对逻辑执行计划进行优化,最后由执行器将逻辑执行计划转换为物理执行计划。
- MetaStore:存储Hive表的元数据。默认是存储在 Hive 自带的 Derby 数据库中的,一般会通过配置将其存储到 MySQL 中。
Hive MetaStore
Hive Metastore:作为Hive表与HDFS上以文件形式存在的数据之间的桥梁,它存储了 Hive 中所有表的元数据,包括表的名称和位置,列的名称和类型等。任何具有 JDBC 驱动程序的数据库都可以作为元数据库(metabase)。Hive 内置的 Derby 数据库就是一个元数据存储。
Metastore 有三种配置方式
- 内嵌模式:元数据存储在内置的 Derby 数据库,并且 Derby 数据库和 metastore 服务都嵌入在主 HiveServer 进程中,当启动 HiveServer 进程时,Derby 和 Metastore 都会启动
- 本地模式:本地模式采用外部数据库来存储元数据,如MySQL。Hive Metastore 服务与主 HiveServer 进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。Metastore 服务将通过 JDBC 与 Metastore 数据库进行通信。
- 远程模式:远程模式(Remote Metastore)下,Metastore 服务在其自己的单独 JVM 上运行,而不在 HiveServer 的 JVM 中运行。还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性
内部表与外部表
外部表不会将数据移动到自己的数据仓库目录下,只是在元数据中存储了数据的位置。而内部表将数据移动到自己的数据仓库目录下,数据的生命周期由 Hive 来进行管理
索引
索引的设计目标是提高表某些列的查询速度。如果没有索引,带有where的查询会加载整个表或分区并处理所有行。但是如果where语句对应的列存在索引,则只需要加载和处理文件的一部分。
在指定列上建立索引,会产生一张索引表。里面的字段包括:索引列的值、该值对应的 HDFS 文件路径、该值在文件中的偏移量。在查询涉及到索引字段时,首先到索引表查找索引列值对应的 HDFS 文件路径及偏移量,这样就避免了全表扫描。
索引表最主要的一个缺陷在于:索引表无法自动 rebuild,这也就意味着如果表中有数据新增或删除,则必须手动 rebuild,重新执行 MapReduce 作业,生成索引表数据。
分区表和分桶表
分区表和分桶表的本质都是将数据按照不同粒度进行拆分,从而使得在查询时候不必扫描全表,只需要扫描对应的分区或分桶,从而提升查询效率
- 分区:partitionBy
分区为 HDFS 上表目录的子目录,数据按照分区存储在子目录中。如果查询的 where 字句的中包含分区条件,则直接从该分区去查找,而不是扫描整个表目录,以提高查询性能。在 Hive 中可以使用 PARTITIONED BY 子句创建分区表。表可以包含一个或多个分区列,Hive会为分区列中的每个不同值组合创建单独的数据目录 - 分桶:clusteredBy
并非所有的数据都可以进行合理的分区,分区的数量很多也会对文件系统造成负担,因此Hive提供了分桶这样一个更细粒度的数据拆分方案。分桶表会将指定列的值进行哈希散列,并对 bucket(桶数量)取余,然后存储到对应的 bucket(桶)中
分桶的实质是对指定字段做了 hash 散列然后存放到对应文件中
Hive优缺点:
优点:
- 上手门槛相对较低:Hive的出现大大降低了MapReduce的使用门槛,使得只会SQL不会Java的人也能进行大数据分析
- 提供了表级别的元数据管理
不足:
- Hive需要基于独立的metastore来提供数据表元信息查询,在数据分区特别大的情况下metastore的性能不足,这导致一些分区多的数据表上的查询分析性能不能满足业务需求