Spark Shuffle机制
Shuffle机制
Apache Spark是一个强大的分布式计算框架,它能够高效地处理大规模数据集并加速数据处理过程。其中一个关键的特性就是其Shuffle机制,理解Spark的Shuffle机制对于理解Spark作业的执行至关重要。本文将分别介绍Spark的Shuffle Write阶段和Shuffle Read阶段,并在最后与MapReduce Shuffle机制进行比较。
简介
Shuffle解决的是上下游stage之间传递数据的问题。Shuffle机制分为Shuffle Write和Shuffle Read两个阶段,前者主要解决上游Stage输出数据的分区问题,后者主要解决下游Stage从上游Stage获取数据、重新组织、并为后续操作提供数据的问题。
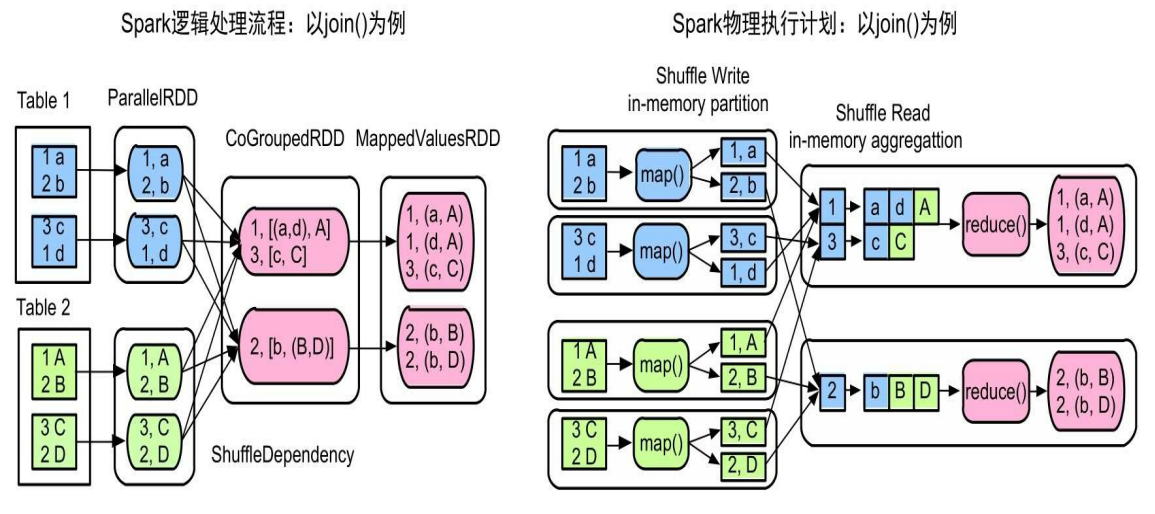
以join操作为例的Spark Shuffle过程:
Shuffle Write
Spark的Shuffle Write过程包含数据聚合,排序,分区三个步骤,其中分区是必备步骤,聚合和排序是可选步骤。
- 聚合:进行聚合combine操作的目的是减少Shuffle的数据量。只有包含聚合函数的数据操作才需要进行Shuffle Write时的combine,例如aggregateByKey(), reduceByKey(), distinct()等。
- 排序:可根据partitionId+key或者只根据partitionId进行排序
- 分区(Required)。在partition时,Spark根据partitionId将record依次输出到不同的buffer中,每当buffer填满就将record溢写到磁盘上的分区文件中。使用buffer的原因是map()输出record的速度很快,需要进行缓冲来减少磁盘I/O
下图展示了一个包含聚合和排序操作的Shuffle Write流程:
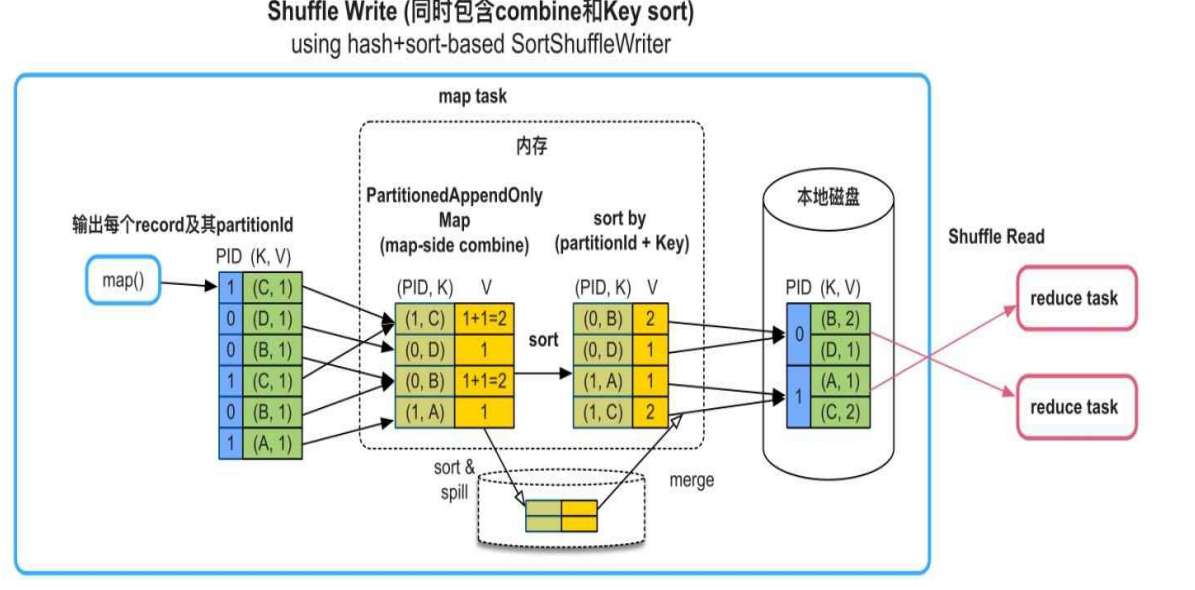
注:Shuffle Write的分区个数与下游Stage的task个数一致,这个分区个数可以由用户自定义,如groupByKey(numPartitions)中的numPartitions。如果用户没有定义,则默认分区个数是父RDD的分区个数的最大值
Shuffle Read
Spark的Shuffle Read过程包含数据获取,聚合,排序三个步骤。其中数据获取是必备步骤,聚合和排序是可选步骤。
- 数据获取(Required):从上一个stage中的task获取record,并将record输出到buffer中,下一步操作就可以直接从buffer中获取数据。
- 聚合:获取record后,Spark建立一个类似HashMap的数据结构(ExternalAppendOnlyMap)对buffer中的record进行聚合。HashMap中的key是record中的key,value是经过聚合函数计算后的结果。
- 排序:如果需要对key进行排序,则建立一个Array结构,读取HashMap中的record,并对record按key进行排序。
下图展示了一个包含聚合和排序操作的Shuffle Read流程:
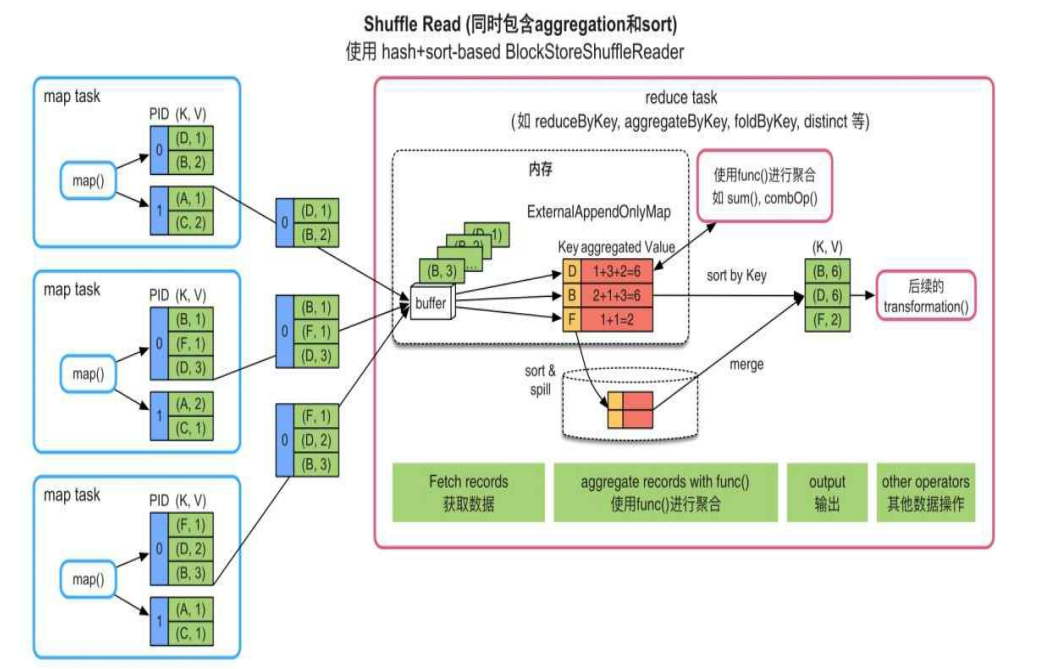
注:Shuffle中使用的数据结构都试图在内存中进行聚合和排序,如果内存放不下,则进行扩容。如果扩容还放不下,就将数据spill到磁盘上,最后将磁盘和内存中的数据进行merge得到最终结果。
与MapReduce Shuffle的区别
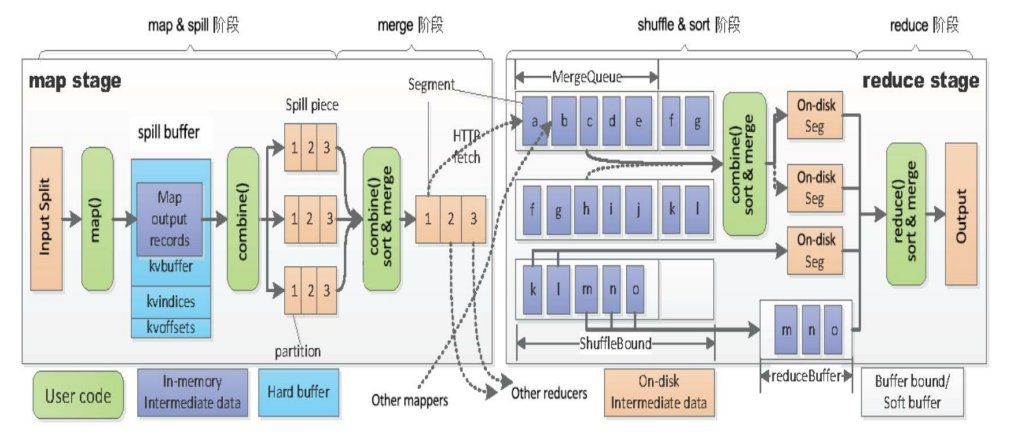
- MapReduce不能在线聚合,即无论是map端还是reduce端,都是先将数据存到buffer或spill到磁盘后,再执行聚合操作。而Spark是随着map的不断输出,在内存中使用hashMap来进行聚合的。
- MapReduce在shuffle write时严格按照key排序,但对于groupByKey()这样的操作不需要严格按照key进行排序。而Spark在shuffle write时的排序比较灵活,可以根据partitionId+key排序,也可以根据partitionId排序,或者不排序。
参考资料
- 许利杰,方亚芬. 大数据处理框架Apache Spark设计与实现[M]. 电子工业出版社, 2021.